
A key approach within data-centric AI is to use the available data to gain a better understanding about the data that is shaping the model and then let the model guide you towards anomalies in the data, which you then use to reconfigure your datasets or even include or remove certain data to see the impact that it has on the model behavior.
So you need a mechanism that allows you to not only understand the data better, but also be able to quickly see the impact that the changes have on the data.
As soon as you upload the data, the Acharya Dashboard provides you immediate feedback in the form of the following reports. These are simply based on your data without running your models yet.
Use entity distribution to determine your entity bias
Entity distribution shows how many annotations belongs to each entity. If the number of annotations of a particular entity is less or more as compared to other entities, you can make out that the dataset is biased against or towards that entity. So this view gives an insight into what kind of new data should be sourced into the project to balance the entity distribution.

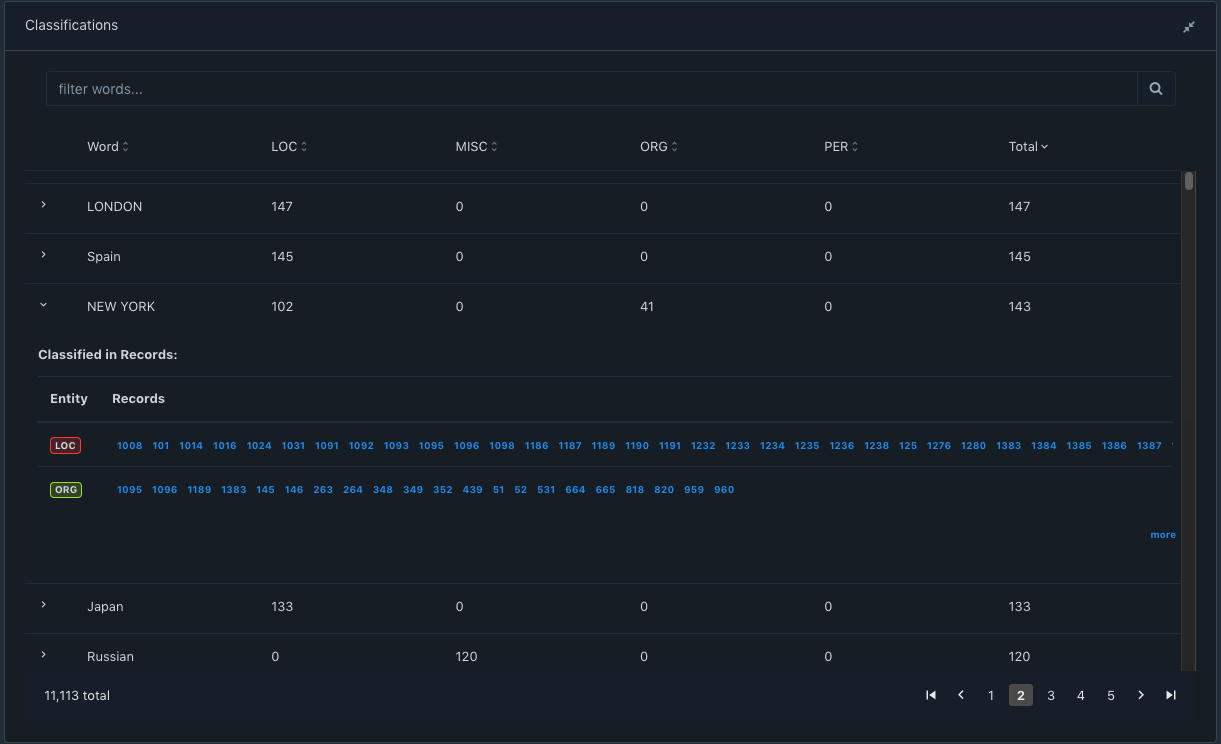
Classifications
This table lists the words classified against each entity. This view helps in identifying words from your text corpus that are classified as entities. If a word is classified as more than one entity then it is important to verify such annotations and confirm the validity of that annotation. This table also helps to know the count of occurrences of each annotated word in the dataset. In the screenshot below, the work NEW YORK is classified as a LOC in 102 records and as ORG in 41 records. Clicking on NEW YORK expands the list, and helps you navigate to the specific record where you can review the text to confirm if the classification is valid.
Missed Classifications
Often it so happens that while annotating, you might have either missed classifying the word or might have wrongly classified that word. It may also happen that you marked that word once, but missed at other locations simply because of time constraints. It is to identify such misses that we built Missed classifications. This again is a very helpful view that displays the words that have been classified once in the dataset and missed at other locations of the dataset.
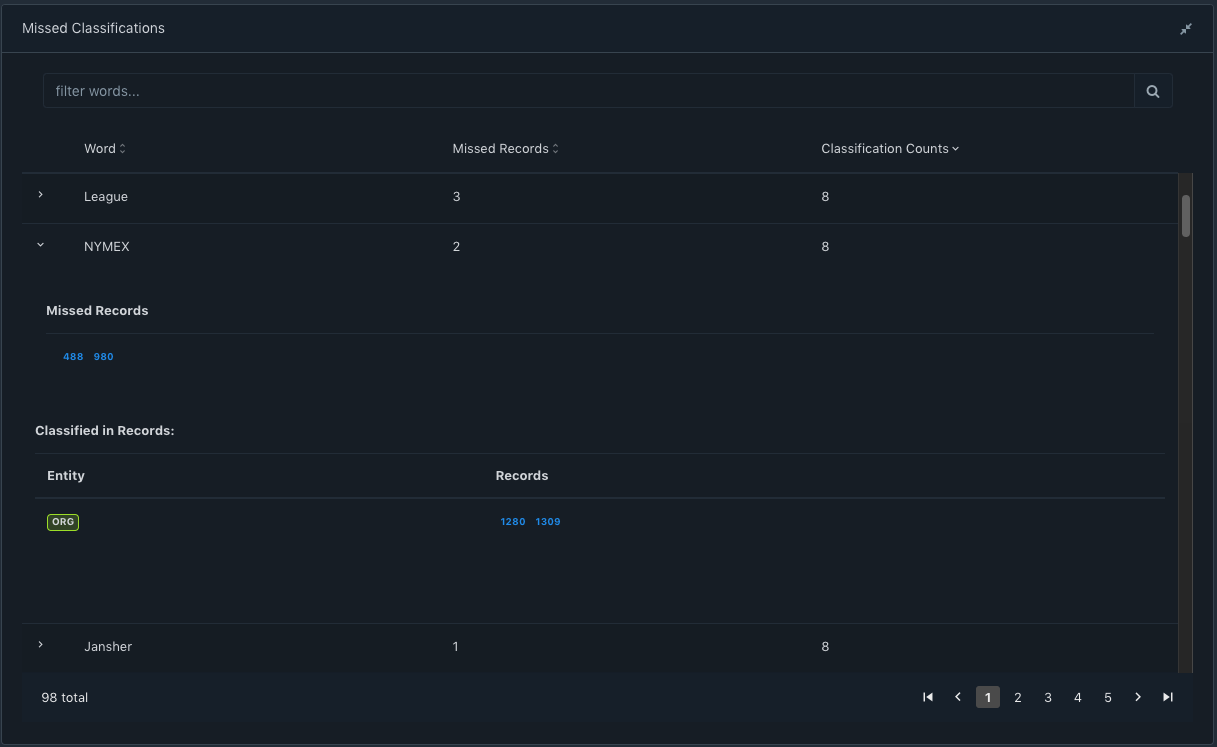 Sorting on Missed Records would let the user know annotations which might have been missed by the annotator And sorting on Classification Counts would let the user know annotations that might have been wrongly annotated by the annotator.
Sorting on Missed Records would let the user know annotations which might have been missed by the annotator And sorting on Classification Counts would let the user know annotations that might have been wrongly annotated by the annotator.Anomalies
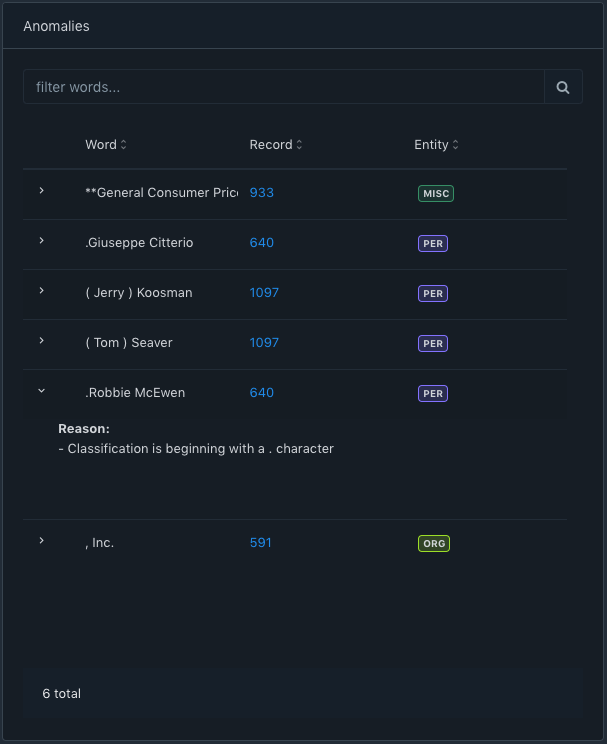
Anomalies highlight those annotations where Acharya feels the annotation might be a mistake. As seen in the screenshot below, the annotator has included unnecessary symbols into the word. Often when classifying multiple records, or when using a classification service such mistakes crop in.
Like with the other views, Acharya makes it easy to jump to the record in question and correct the annotation in the underlying data.
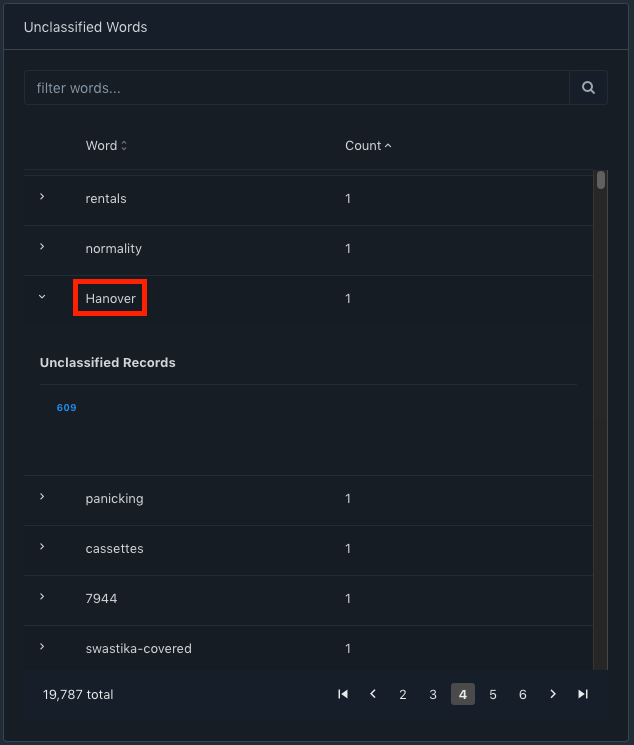
Unclassified words
This is another feature we felt is important as you review your data. This simple table helps in identifying unclassified words in the dataset. Instead of browsing the dataset, this table helps sort the words based on their word length and number of occurrences.
We will continue our exploration of the data centric features and reports in Acharya in Part 2. In the meantime, feel free to let us know what are your favorite features and also share what your experience has been using Acharya. The link to Acharya is in the bio.