
Continuing our tour of data-centric features in Acharya that we began in Part 1, in Part 2, we will continue our exploration of some of the data-centric features in Acharya that can increase your efficiency as an annotator as well as potentially improve your ML models. Let's say you have trained your algorithm on your dataset three times. Please refer to the Acharya documentation for details on how to start a training of your configured algorithm on your project dataset.
Let's say you have configured 3 models for training on your dataset. Please refer to the Acharya documentation for details on how to configure your models for training in Acharya.
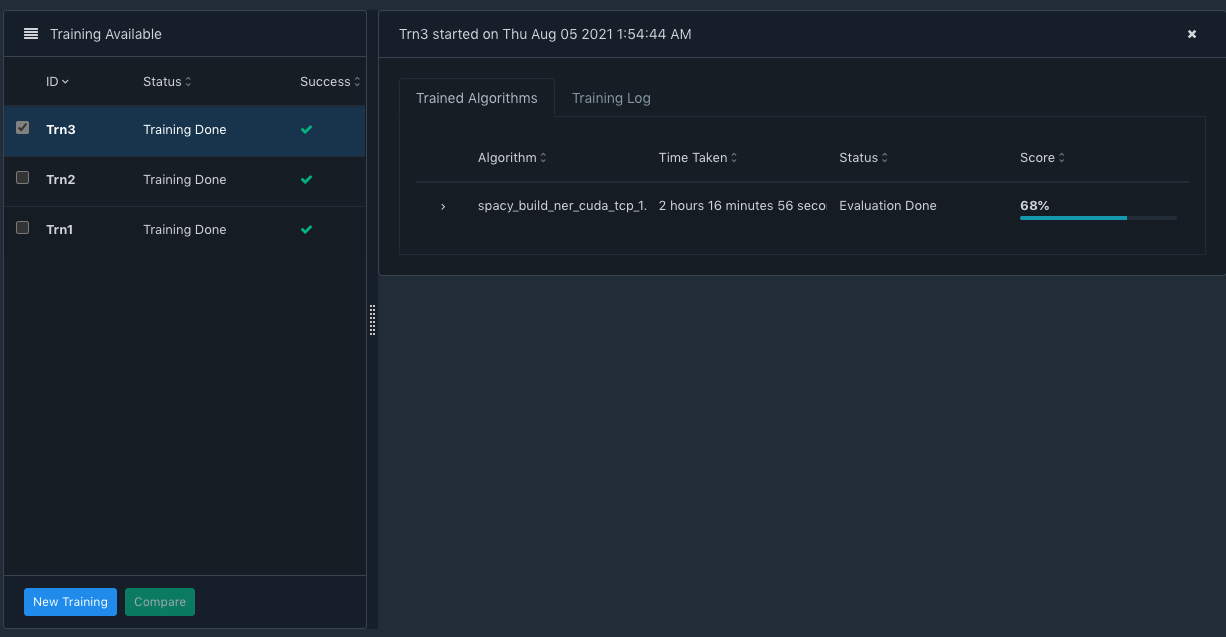
In the screenshot above, the left side pane shows the three trainings. Trn3 is selected, which expands the details on the right side pane. You can see the algorithm, the time it took, its status and its Score.
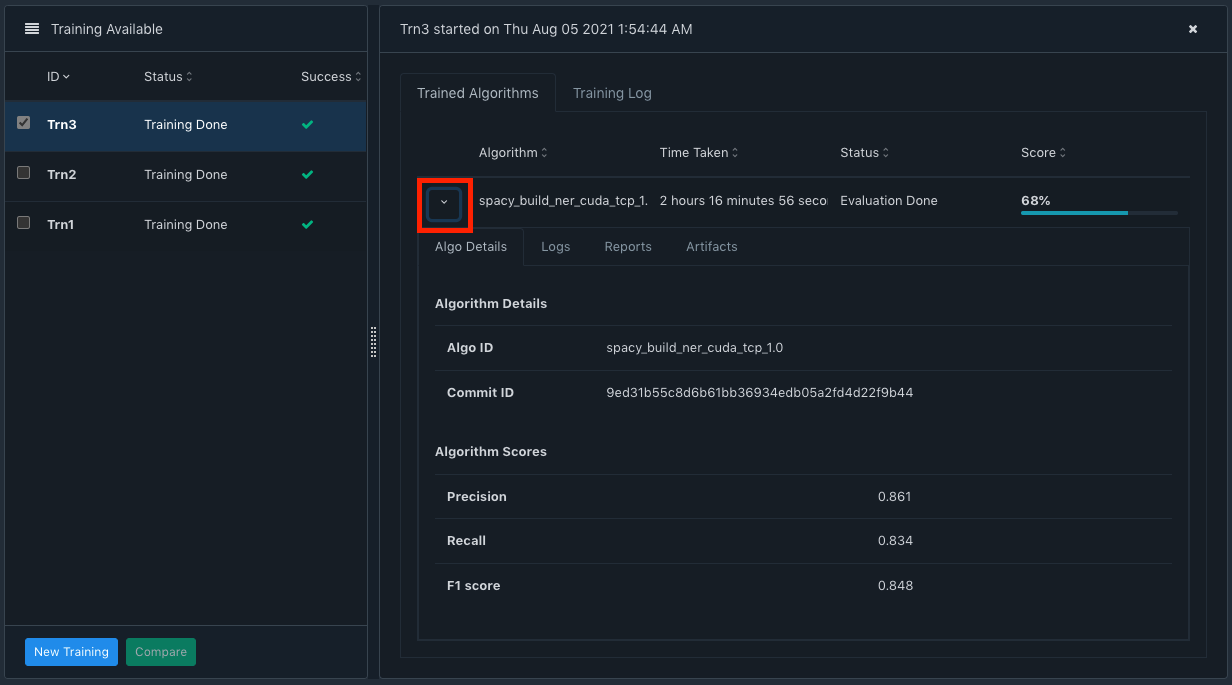
As in the screenshot above, you can view the details of the training run by expanding the highlighted arrow (red square box). In the Algo Details tab, you can see the Precision, Recall and the F1 score. Do note the Git commit ID. For an MLOps tool, we believe that Git support is a key requirement and like engineering code, even ML code should be version controlled in a mature MLOps implementation.
Switching to the Reports tab, you are able to further drill down to the Entity level performance of the Trn3.
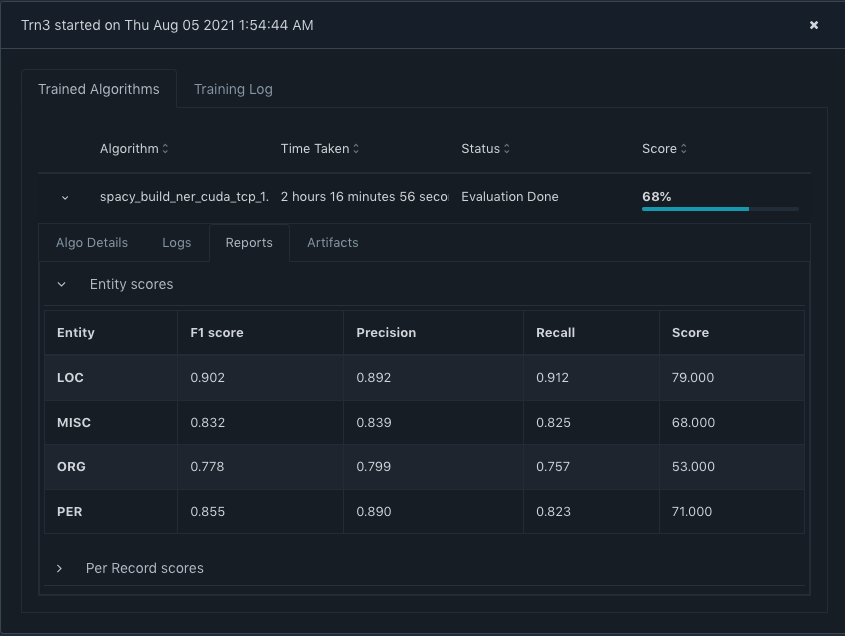
You can also see the Per Record scores by expanding the 'Per Record scores' section.
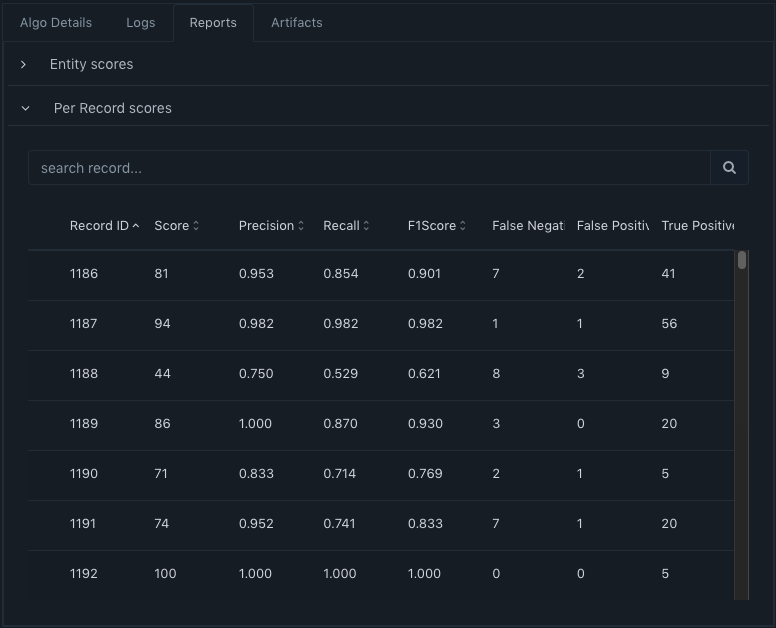
This helps you to identify how well the trained model performs on the individual records marked for evaluation. In this view, you must also peruse the columns like Precision, Recall, False Negative, True Positive etc. and find annotation errors and fix those annotations appropriately in the evaluation records. This can have an impact on the score. We have seen incorrectly annotated data being skipped by the model. When we fixed the annotation, which was highlighted to us by this view - the model was able to classify the validation data appropriately increasing the score of the model. Likewise, you can go back to see all the Trainings, choose two runs to compare their details, and even see the Best performing training run to identify the potential production candidate. This comparison will show you a diff about the algorithm code as well as the data [ please note - in Acharya Community Edition, this comparison has to be executed using the command-line interface ].
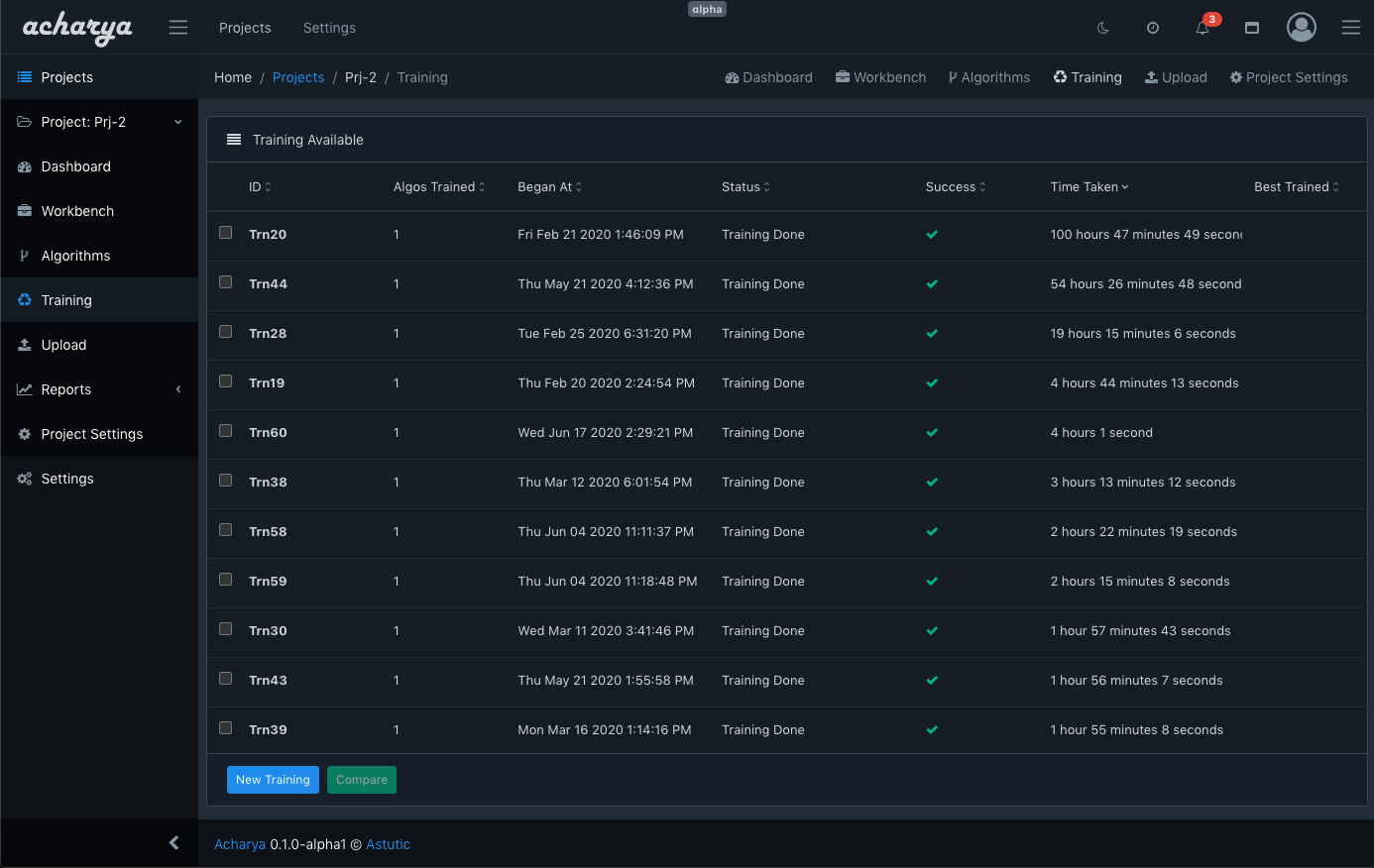
The ease with which Training experiments can be executed is a key feature of Acharya. The insights about how the trained model performed on individual evaluation records combined with the other data centric features that was discussed in Part-1, the ability to tune the model by tweaking the data becomes much simpler with Acharya. This helps in improving the efficiency of your NER model development process.