Annotating and Curating the uploaded data
Annotating the data
Once the data in uploaded to a project, the data can be annotated in Workbench accessible via the sidebar.
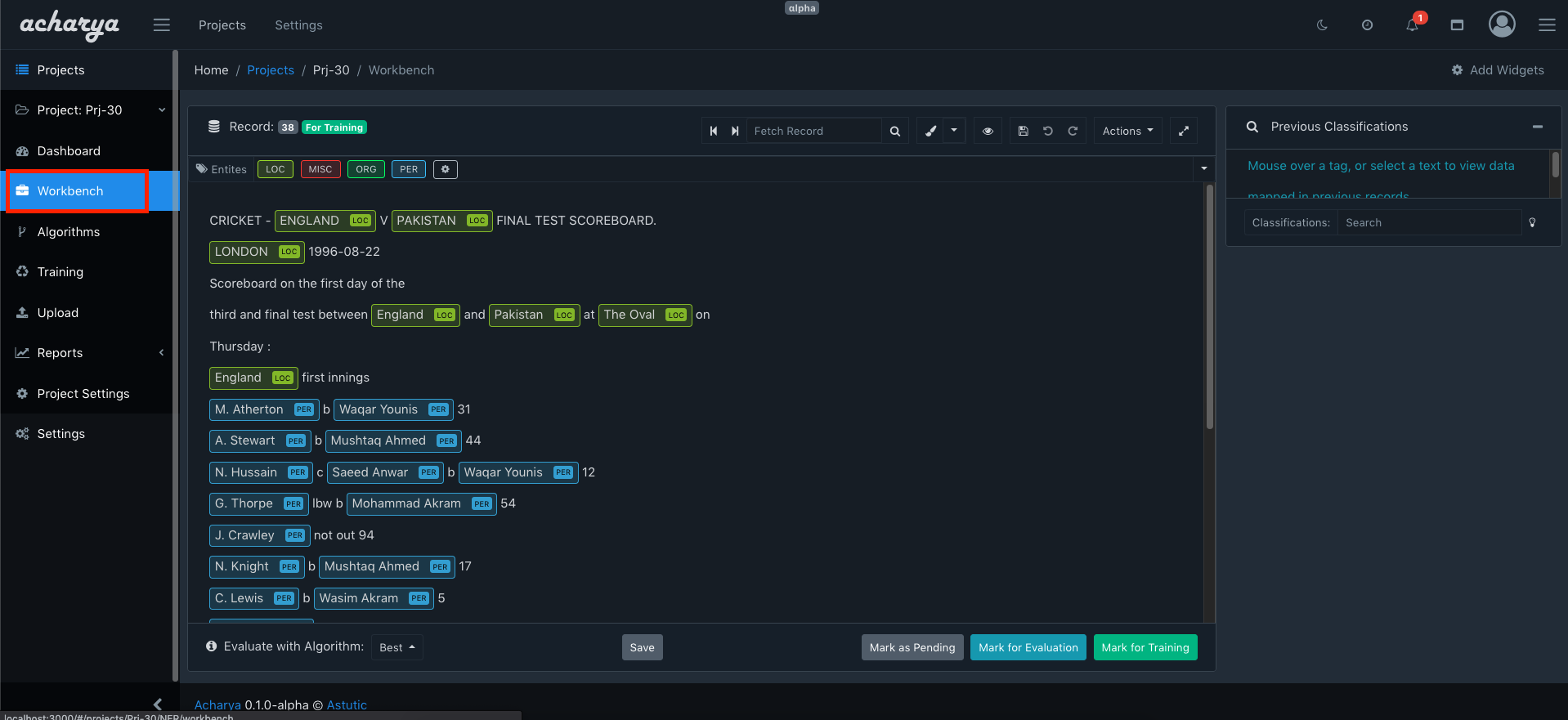
To learn more about how to use Workbench and its various features see Using Workbench.
Once the data is annotated a data-centric report about the annotation suitable for NER would be available in the Dashboard. These reports help in further improving the annotation quality and data changes if required. The dashboard currently shows the following reports which help as explained
Check entity data bias from entity distribution
Entity distribution shows how many annotations belongs to each entity. If the number of annotations of a particular entity is less or more as compared to other entities, it shows that the dataset is biased against or towards that entity. This report gives an insight that what kind of new data should be sourced into the project to balance the entity distribution.
Classifications
Classifications list the words classified against each entity. This table helps in identifying words which are classified as what entities. If a word is classified as more than one entity then it is important to verify such annotations and confirm the validity of that annotation.
This table also helps to know the occurrences of each annotated words in the dataset.
Missed Classifications
Missed classifications show the words that have been classified once in the dataset and missed at other locations of the dataset. This is very important to identify mistakes where the annotator might have either missed classifying the word or might have wrongly classified that word.
Sorting on Missed Records would let the user know annotations which might have been missed by the annotator
And sorting on Classification Counts would let the user know annotations that might have been wrongly annotated by the annotator.
Anomalies
Anomalies highlight those annotations where the system feels the annotation might be a mistake. This might need annotation correction of the underlying data to be modified.
Unclassified words
This table helps in identifying unclassified words in the project. Instead of browsing the dataset, this table helps sort the words based on their word length and number of occurrences.